2026年人们如何制作逼真AI视频?真实工作流程、工具及常见误区

人们正在通过结合短AI生成片段、参考图像、图像转视频模型、视频超分辨率、剪辑、声音设计和色彩校正来制作逼真的AI视频。最逼真的AI视频通常并非一键生成。它们是通过一套可重复的制作流程打造的:规划场景、创建或收集参考图像、生成多个短片段、选择最清晰的输出、将它们拼接起来、添加画外音或音乐、提升素材分辨率,并对最终视频进行精修。
初学者AI视频与逼真AI视频的最大区别,不仅在于工具,更在于工作流程。
在我的用户研究和制作分析中,一个模式反复出现:逼真的AI视频创作者很少只依赖单一生成器。他们通常会结合使用Kling、Runway、Luma、Veo、Midjourney、Topaz、ComfyUI、本地视频模型、语音工具、音乐工具和剪辑软件等。某个工具可能生成第一个片段,另一个工具可能将其延长,再一个工具可能创作音乐,还有一个工具可能提升最终素材的分辨率。最终的逼真效果源于整个制作流程,而非一键生成。
本指南将深入探讨人们如何真正制作逼真的AI视频,大多数创作者为何偏爱短片段、哪些工具适用于不同场景、AI视频为何仍显虚假,以及如何为社交视频、广告、短片、虚拟形象和教育内容构建实用的工作流程。
对于希望以更结构化的方式将脚本、文档、幻灯片或培训材料转化为专业AI视频的团队,Leadde 提供了一套AI视频创作工作流程,帮助您将现有内容转化为精美的视频,无需从零开始编写提示词。
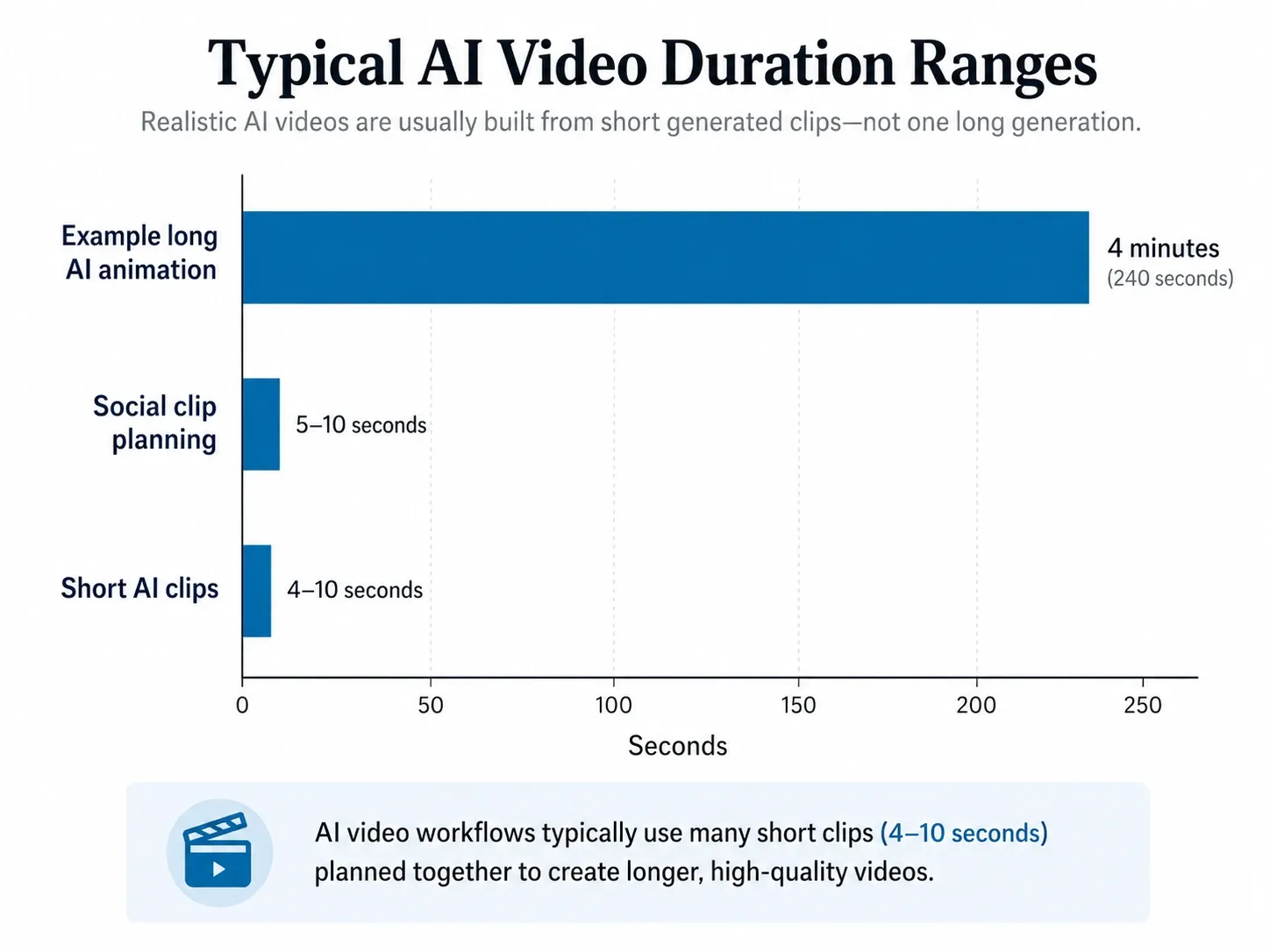
为什么逼真的AI视频通常由短片段而非长视频构成
大多数逼真的AI视频都由短片段组成,因为当前的AI视频模型在生成可控的短瞬间方面,仍优于生成连续的长场景。在实际制作流程中,创作者通常会生成许多4-10秒的片段,从中挑选最佳部分,然后剪辑成完整的视频。
这是初学者最常误解的关键点之一。
一个精美的AI视频表面上可能看起来浑然一体,但幕后往往是由一系列短小的生成镜头构成。每个镜头都经过测试、淘汰、重新生成、修剪、拼接和精修。最终视频之所以流畅无缝,是规划和剪辑的功劳,而非模型一次性完美生成了整个内容。
当前AI视频模型在短片段中表现最佳
短片段更易于控制,因为模型只需在几秒钟内保持面部、身体、背景、光照和动作的一致性。一旦片段变长,视觉漂移的风险就会增加。
常见问题包括:
- 角色面部缓慢变形。
- 手臂或手部出现扭曲。
- 身体动作不自然。
- 镜头无目的地漂移。
- 服装或背景细节在帧之间发生变化。
- 主体在开始时逼真,但到结尾时变得怪异。
这就是为什么许多逼真的AI视频创作者将AI视频生成视为“镜头制作”,而非传统的“录制”。他们不会要求模型制作整部电影,而是让它一次只生成一个可用的镜头。
一个实用的逼真AI视频工作流程通常如下:
场景构思
→ 参考图像
→ 4-10秒AI视频片段
→ 重新生成多个版本
→ 选择最清晰的输出
→ 为下一场景重复此步骤
→ 剪辑片段
→ 添加画外音、音乐、音效、字幕
→ 超分辨率和色彩校正
→ 发布
为什么长AI视频需要反复生成和剪辑
较长的AI视频需要更多次重新生成,因为每个片段都存在失败风险。在我的研究中,制作严肃AI视频项目的创作者,往往需要多次生成同一个短片段才能获得干净的结果。
一个Veo 3的演示案例揭示了这如何迅速成为一个生产问题。创作者拥有1,000点积分,每次生成消耗100点。理论上,这允许生成约10次。为了完成一个小演示,他们使用了两个教育账户,进行了大约20次尝试,才制作出5个可用的片段。其中两个片段一次成功,而另外三个则分别需要3-6次生成。
这个例子揭示了逼真AI视频制作的一个隐藏真相:真正的成本不仅是订阅费,更是失败的尝试。
一个5秒的片段看似简单,但如果需要五次生成才能获得一个干净的结果,时间和积分成本就会迅速倍增。对于一个包含六个镜头的30秒视频,这可能意味着几十次生成。对于一个4分钟的AI动画,则可能需要数百次测试。
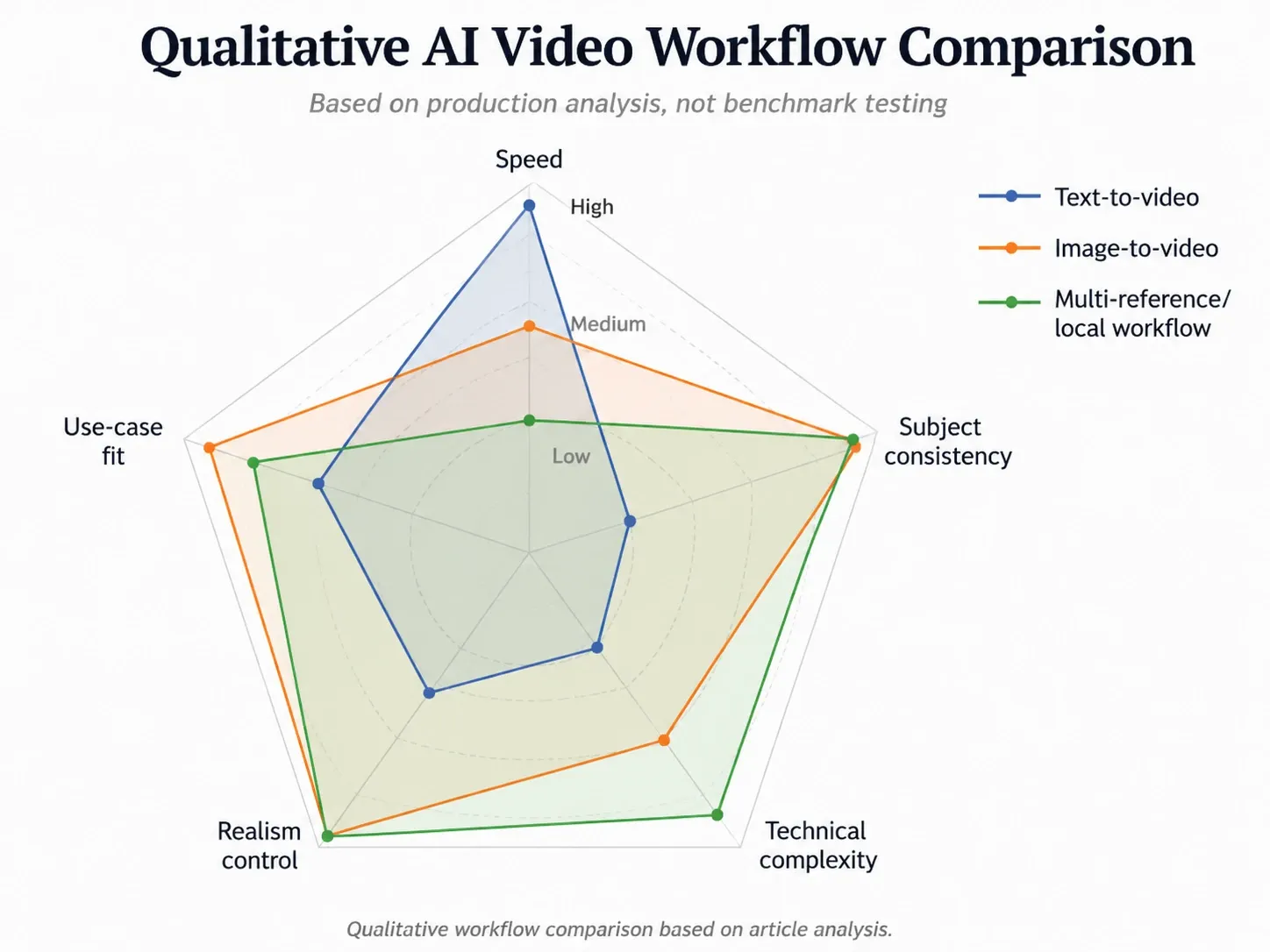
真实工作流程:生成、选择、拼接、精修
最优秀的AI视频创作者通常不会强求模型完成所有任务。他们采用的是一种制作思维:
- 生成多个短片段选项。
- 选择视觉问题最少的片段。
- 在剪辑软件中将它们拼接起来。
- 通过剪切、字幕、声音或转场来隐藏有缺陷的帧。
- 添加最终精修,使视频看起来像真实素材。
这就是为什么逼真的AI视频不仅是提示词技巧,更是剪辑技巧。
如果你的AI视频仍然显得虚假,问题可能不在于你的提示词,而是你期望模型完成本应在剪辑、声音设计和后期制作中完成的工作。
大多数创作者使用的逼真AI视频工作流程
制作逼真AI视频最可靠的方法是采用多步骤工作流程,而非仅仅依赖单一文本提示词。以下工作流程基于我在真实创作者项目、工具测试和实际制作案例中发现的模式。
步骤1:从场景规划开始,而非仅仅提示词
逼真的AI视频应从场景规划开始。仅仅一个提示词是远远不够的。
许多初学者会编写冗长的提示词,其中充满了摄影术语、光照描述和风格词汇。这可能有所帮助,但并未解决核心问题:模型需要一个清晰简单的动作来生成。
在编写提示词之前,请明确:
- 主要主体是谁或什么?
- 主体正在做什么?
- 片段应该多长?
- 摄像机是静止还是移动?
- 什么应该保持一致?
- 镜头中什么应该发生变化?
- 这个片段是否与另一个片段连接?
例如,与其要求:
“一个电影感的逼真男人,穿梭于未来城市,戏剧性光照,情感氛围,皮肤细节,动态镜头,逼真动作,4K,超现实。”
一个更强的制作提示词会专注于一个受控动作:
“一个疲惫男人在雨夜城市街道缓慢行走的逼真特写镜头。摄像机在他身旁跟踪拍摄。湿漉漉的路面反射着霓虹灯。他的面部保持一致,表情严肃,动作自然。”
第二个提示词更好,因为它为模型提供了一个主体、一个动作、一个摄像机运动和一个环境。
对于逼真的AI视频,每个片段都应完成一个明确的任务。
步骤2:创建或选择高质量参考图像
参考图像是制作逼真AI视频最重要的环节之一。如果你想要一致的角色、产品、动物或环境,图像转视频通常比文本转视频更具可控性。
一张高质量的参考图像应具备:
- 一个清晰的主体。
- 干净的光照。
- 最少的背景干扰。
- 可辨识的面部或产品形状。
- 与预期动作相符的姿态。
- 接近最终视频风格。
如果参考图像过于拥挤,模型可能会难以处理。全身镜头、复杂服装、杂乱背景、多个人物和不清晰的光照都可能增加扭曲的可能性。
对于人物和虚拟形象,清晰的面部参考至关重要。对于产品视频,产品形状应清晰。对于动物,身体姿态不应过于复杂。对于电影场景,参考图像中的光照和摄像机角度应已接近所需的最终镜头。
这就是为什么Midjourney等工具常用于工作流程的初期。它们有助于在视频生成步骤开始前,创建角色、地点、情绪板、背景素材和视觉风格参考。
步骤3:使用图像转视频确保一致性
如果你的目标是逼真度,图像转视频通常比文本转视频提供更多控制。
文本转视频适用于快速实验、抽象场景、超现实视觉效果,以及主体无需保持精确一致的创意。但如果你需要逼真的人物、产品、动物、房间、车辆或品牌资产保持一致,图像转视频通常是更稳妥的工作流程。
在以下情况使用文本转视频:
- 你正在探索初步创意。
- 你不需要在不同镜头中保持同一角色。
- 场景是抽象、奇幻或超现实的。
- 速度比控制更重要。
在以下情况使用图像转视频:
- 你需要一致的人物或产品。
- 你想制作逼真的社交媒体片段。
- 你正在制作广告或UGC(用户生成内容)风格的视频。
- 你想保留光照、构图或身份特征。
- 你需要连接多个镜头。
在以下情况使用多参考或本地工作流程:
- 你正在制作短片。
- 你需要重复出现的角色。
- 你想要更强的身份控制。
- 你熟悉ComfyUI或本地模型工作流程。
- 你需要比消费级工具提供更多的技术控制。
步骤4:生成多个短片段,只保留干净的
逼真的AI视频制作是一个筛选过程。你应该预期生成比实际使用更多的版本。
在审阅生成的片段时,请注意:
- 面部稳定性。
- 自然的身体动作。
- 干净的手臂和手部。
- 一致的服装。
- 稳定的光照。
- 逼真的摄像机运动。
- 无奇怪物体变形。
- 无突然的背景变化。
- 首帧或尾帧无明显故障。
一个简单的经验法则是:不要试图修复每一个有缺陷的片段。生成更多选项,选择最干净的。
在许多情况下,提高逼真度最快的方法不是编写更长的提示词,而是更快地淘汰有缺陷的输出。
步骤5:将片段剪辑成故事
最逼真的AI视频不仅仅是精美的片段,它们拥有结构。
在我对AI视频账户和创作者工作流程的分析中,优秀的视频通常具有清晰的构思、吸引点和序列。视觉质量固然重要,但脚本和结构对于观众留存更为关键。
一个逼真的AI视频应回答:
- 为什么观众应该观看前2秒?
- 从开始到结束有什么变化?
- 每个片段都有其目的吗?
- 节奏是否过慢?
- 有缺陷的帧是否被隐藏或移除?
- 视频感觉像一个故事、广告、演示还是场景?
这对于TikTok、Instagram Reels、YouTube Shorts和AI广告创意尤为重要。一个视觉上令人印象深刻但缺乏核心创意的视频,往往感觉像一个演示。一个略有瑕疵但具有强大吸引点和清晰故事的视频,反而可能表现更好。
步骤6:添加画外音、音乐、声音设计和字幕
声音是逼真度的重要组成部分。许多AI视频之所以显得虚假,是因为它们感觉寂静、空洞或与场景脱节。
真实视频富有质感。它们包含脚步声、风声、房间噪音、织物摩擦声、交通声、背景人声、摄像机操作声、呼吸声、音乐和微妙的环境音。
要让AI视频感觉更逼真,请添加:
- 画外音。
- 对白。
- 必要时进行唇形同步。
- 背景音乐。
- 环境音效。
- 拟音细节。
- 字幕。
- 自然的停顿和节奏。
对于AI虚拟形象和“讲话头”视频,声音的重要性往往与面部不相上下。逼真的面部配上机械音,仍然会显得虚假。如果你正在学习如何为员工入职培训制作AI虚拟形象视频,自然的语音、时机和字幕能让视频更具可信度。
步骤7:超分辨率、色彩校正和添加胶片颗粒
最终精修是许多AI视频得以发布的关键环节。
AI视频生成器通常能产生视觉上令人印象深刻的输出,但并非完全成品。素材可能过于平滑、饱和度过高、过于干净、过于锐利,或在不同片段之间缺乏一致性。
后期制作可以帮助解决这些问题。
常见的后期处理步骤包括:
- 视频超分辨率。
- 提升帧质量。
- 统一片段间的色彩。
- 降低过饱和度。
- 添加微妙的胶片颗粒。
- 适时添加运动模糊。
- 调整对比度。
- 清理转场。
- 以正确的分辨率和比特率导出。
Topaz等工具常用于超分辨率和增强。但仅仅超分辨率并不能创造逼真度,它只改善了最终的表面质量。更深层次的逼真度仍源于良好的参考、受控的动作、仔细的筛选、剪辑、声音和色彩一致性。
人们正在使用哪些工具制作逼真的AI视频?
对于每个逼真的视频项目,没有单一的最佳AI视频工具。更好的问题是:哪个工具适合你正在制作的场景?
不同的工具解决了逼真AI视频工作流程中的不同环节。有些擅长图像生成,有些擅长图像转视频,有些擅长延长片段,有些擅长唇形同步,有些擅长超分辨率,还有些擅长高级本地控制。
Kling:逼真动作和连贯短片段的最佳选择
Kling常用于制作逼真的短片段、基于参考的动作、慢速电影感场景和连贯的视觉输出。在实际工作流程中,当参考图像清晰且所需动作不复杂时,它表现出色。
Kling尤其适用于:
- 逼真的短视频。
- 图像转视频生成。
- 电影感慢动作。
- 超现实但连贯的场景。
- 娱乐片段。
- 基于参考帧的混剪风格视频。
局限性在于,Kling仍可能产生扭曲,尤其是在全身镜头、复杂姿态、拥挤场景或参考图像中视觉元素过多时。它也可能需要多次生成才能获得一个足够干净可用的片段。
最佳用例:场景、主体和动作明确定义的逼真短片段。
Runway:创意镜头、唇形同步和视觉实验的最佳选择
Runway适用于创意视觉实验、风格化镜头、营销活动概念、音乐视频和某些唇形同步工作流程。当目标不是严格的逼真度,而是视觉上有趣的运动时,它通常表现出色。
Runway适用于:
- 创意广告。
- 音乐视频场景。
- 视觉实验。
- AI电影制作测试。
- 唇形同步工作流程。
- 混合媒体视频项目。
局限性在于,根据场景不同,某些输出可能显得缓慢、动画不足或物理上不够自然。对于逼真的动作密集型片段,你可能需要测试多个提示词或将Runway与其他工具结合使用。
最佳用例:视觉风格和灵活性至关重要的创意视频制作。
Luma Dream Machine:延长片段的最佳选择
当目标是延长或连接片段时,Luma通常很有用。许多创作者将其视为更大工作流程的一部分,而非唯一的生成器。
Luma适用于:
- 延长短片段。
- 构建视觉连贯性。
- 连接场景。
- 创造梦幻般的运动。
- 填补镜头之间的空白。
局限性在于,免费或低成本使用可能受限,并且并非每次延长都能保持完美的一致性。
最佳用例:延长片段并构建更流畅的视觉序列。
Veo和Veo 3:高质量输出的最佳选择,但受积分限制
Veo常被认为是高质量AI视频的选择,尤其当目标是在少量镜头中实现令人印象深刻的逼真度时。然而,主要的实际局限性在于积分。
我研究中的Veo 3演示案例就是一个很好的例子。创作者拥有1,000点积分,每次生成消耗100点。理论上,这允许生成约10次。为了完成一个小演示,他们使用了两个教育账户,进行了大约20次尝试,才制作出5个可用的片段。其中两个片段一次成功,而另外三个则分别需要3-6次生成。
这揭示了一个关键的制作教训:高质量并不总是意味着可扩展性。
如果每次失败的生成都消耗积分,创作者可能会变得更加谨慎,减少实验。这会限制创作自由。
最佳用例:高质量演示片段、电影感测试和需要较少最终输出的精选主镜头。
Midjourney:创建参考图像和视觉风格的最佳选择
Midjourney并非视频生成器,但它在逼真AI视频工作流程的初期通常非常有用。
它有助于创建:
- 角色概念。
- 背景。
- 产品场景。
- 情绪板。
- 电影感画面。
- 视觉参考。
- 故事板图像。
一张高质量的Midjourney图像可以成为图像转视频片段的基础。当你需要在将图像导入Kling、Runway、Pika、Luma或其他视频工具之前保持一致的风格时,这尤其有用。
最佳用例:创建参考图像、视觉方向和一致的风格资产。
Topaz:超分辨率和最终增强的最佳选择
Topaz通常在工作流程的末端使用,用于提升素材分辨率、改善清晰度并提高感知到的制作质量。
Topaz适用于:
- 视频超分辨率。
- 帧增强。
- 谨慎使用时的锐化。
- 提升最终导出质量。
- 使片段更显精美。
但Topaz无法修复糟糕的动作、扭曲的解剖结构或不一致的身份。它是一个后期处理工具,而非逼真度引擎。
最佳用例:在已有干净片段后的最终精修。
ComfyUI、Wan和本地模型:高级控制的最佳选择
高级创作者在需要对身份、参考、成本或自定义进行更多控制时,常使用本地工作流程。
本地工作流程适用于:
- 本地生成。
- 多参考控制。
- 角色一致性。
- 更低的边际生成成本。
- 自定义模型工作流程。
- 实验性流程。
- 隐私敏感型制作。
权衡在于复杂性。你可能需要安装ComfyUI、下载模型、配置工作流程、管理GPU资源并学习技术设置。
最佳用例:需要更多控制而非简单操作的高级创作者。
如何让AI视频看起来更逼真
要让AI视频看起来更逼真,请使用参考图像、保持每个片段简短、生成多个版本、通过剪辑隐藏有缺陷的帧、添加逼真的音频,并通过色彩校正和超分辨率精修最终素材。
逼真度并非单一设置,而是众多细微制作选择的综合结果。
使用参考图像而非仅仅文本提示词
如果你想要逼真的结果,请为模型提供视觉信息。文本提示词可以描述一个人,但参考图像能向模型展示你想要的确切面部、光照、构图和风格。
参考图像对于以下方面尤其重要:
- 人脸。
- 产品视频。
- 动物。
- 逼真的室内场景。
- 时尚。
- 食物。
- 车辆。
- 品牌角色。
- 短片。
一张好的参考图像能减少随机性。它不能消除所有错误,但能为模型提供更强的视觉锚点。
保持每个片段简短而简单
短片段更易于控制。简单的动作更易于生成。
例如:
更好:
- 一个女人转身微笑。
- 一只狗穿过房间。
- 一个产品在桌上旋转。
- 一辆车驶过雨中。
- 一位老师看着镜头讲话。
更难:
- 一个女人跑步、跳跃、拿起包、转身、讲话并挥手。
- 五个人同步跳舞。
- 一只狗跳过家具,同时摄像机旋转。
- 一个产品在城市中漂浮时变形。
- 一个角色在一个连续镜头中与三个人打斗。
如果你需要复杂的动作,请将其分解为更小的镜头。
生成比你认为需要的更多版本
逼真的AI视频制作需要筛选。你应该预期会有失败的生成。
对于你发布的每个片段,你可能需要多次尝试。这是正常的。
在规划视频时,请为以下情况预留预算:
- 失败的动作。
- 面部扭曲。
- 糟糕的手部。
- 光照不匹配。
- 弱化的摄像机运动。
- 低能量输出。
- 奇怪的背景变化。
如果你的工具使用积分,这一点很重要。一个看似只需要六个片段的视频,可能需要30次或更多的生成。
通过剪辑隐藏AI的弱点
剪辑是实现逼真度最强大的工具之一。
你可以通过以下方式隐藏AI的缺陷:
- 在错误出现前剪切。
- 使用特写镜头而非全身镜头。
- 添加切出镜头。
- 使用字幕引导注意力。
- 用音效覆盖弱化的动作。
- 动作剪辑。
- 避免长时间静止拍摄面部或手部。
- 移除首帧或尾帧的不稳定画面。
许多AI视频片段只在几帧内出现问题。好的剪辑可以挽救可用部分。
添加逼真的音频
音频让AI视频充满生命力。
添加与场景匹配的声音:
- 脚步声。
- 风声。
- 雨声。
- 房间环境音。
- 交通声。
- 服装摩擦声。
- 背景人声。
- 开门关门声。
- 物体操作声。
- 自然的画外音。
即使是简单的环境音也能让生成的片段感觉不那么人工合成。
对于社交内容,字幕也同样重要。它们能提高理解度、留存率和可访问性。
像处理真实素材一样精修最终视频
在后期制作中,将最终的AI视频视为真实素材来处理。
在发布之前,请检查:
- 色彩是否一致?
- 素材是否过于锐利或过于平滑?
- 导出看起来是否被压缩?
- 音频是否正确混音?
- 字幕是否可读?
- 视频是否感觉浑然一体?
- 首帧或尾帧是否有可见的故障?
最终精修往往能将一个“酷炫的AI演示”与人们愿意观看的逼真视频区分开来。
人们如何制作逼真AI视频的真实案例
理解逼真AI视频制作的最佳方式是查看真实的工作流程案例。这些案例展示了理论与生产现实之间的差异。
案例研究1:使用免费开源工具制作的本地AI短片
在我的研究中,一个最有用的案例研究涉及一位创作者使用本地生成式AI模型和免费开源工具制作一部电影感短片。
该项目使用的工具和模型包括:
- Z-Image。
- Klein 9b。
- LTX 2.3 I2V。
- VibeVoice。
- 免版税音乐。
- 原创音乐创作。
制作数据尤其有用:
| 制作细节 | 数据 |
|---|---|
| 制作时间 | 大约1周 |
| 长工作日 | 有些日子超过12小时 |
| 直接工具成本 | 0美元(不含电费和GPU成本) |
| 对白行数 | 36+ |
| 角色数量 | 3 |
| 独特输入图像 | 64+ |
这个案例表明,如果你具备运行本地工作流程的技术能力,逼真AI视频可以以非常低的直接成本制作。但它也表明,“免费”并不意味着不费力。
创作者仍然需要:
- 场景规划。
- 角色一致性。
- 图像生成。
- 图像转视频控制。
- 对白制作。
- 音乐选择。
- 剪辑。
- 最终组装。
关键洞察:本地AI工作流程可以降低现金成本,但会增加工作流程的复杂性。对于技术型创作者来说,这可能非常强大。对于初学者而言,更简单的托管工具可能更容易上手。
案例研究2:通过500多次实验制作的4分钟AI动画故事
另一个重要案例涉及一个4分钟的AI动画故事和音乐视频。创作者使用AI生成背景、角色和视觉资产,然后将这些资产动画化为一个完整的故事。
工作流程包括:
- Midjourney用于背景、角色和资产。
- Pika Scenes用于动画。
- Topaz用于超分辨率和帧增强。
制作数据揭示了以下信息:
| 制作细节 | 数据 |
|---|---|
| 最终视频时长 | 4分钟 |
| 实验量 | 500+个生成视频 |
| 预估成本 | 1,000+美元 |
这个案例很重要,因为它打破了AI视频总是廉价和即时生成的迷思。
AI减少了对传统动画制作的需求,但创作者仍然需要测试数百个输出。一个4分钟的AI视频可能需要大量的试错,尤其当目标是视觉连贯性和故事流畅性时。
关键洞察:AI降低了动画制作的门槛,但长篇高质量内容仍需要规划、资金、测试和剪辑。
案例研究3:使用Kling重新构想旧WWE素材
另一个实用的工作流程涉及使用旧的WWE比赛素材作为参考帧来源,然后将这些视觉效果重新构想为超现实但连贯的AI生成片段。
工具对比包括:
- Kling AI。
- Runway Gen 3。
- Minimax。
创作者发现Kling在此特定用例中产生了最连贯的结果。该项目还包含一个重要的制作细节:大约三分之一的最终素材来自原始素材参考。
这是一个很好的例子,说明了如何利用现有素材、旧片段或参考帧来指导AI视频生成。
工作流程如下:
原始素材
→ 导出参考帧
→ 将参考图像输入AI视频工具
→ 使用简单动作提示词
→ 生成超现实变体
→ 选择最连贯的片段
→ 剪辑成最终序列
关键洞察:对于混剪、戏仿、娱乐和超现实视频,参考帧可能比冗长的文本提示词更有价值。当模型有视觉结构可遵循时,其表现会更好。
案例研究4:4-10秒AI片段的多工具流程
一种常见的制作模式是多工具AI视频流程。创作者不会只选择一个工具,而是针对不同任务使用不同的工具。
典型的工作流程可能包括:
- Kling用于逼真的图像转视频片段。
- Runway用于创意镜头或唇形同步。
- Luma用于延长片段。
- Suno用于音乐。
- ChatGPT用于脚本、场景规划和提示词草稿。
- 视频剪辑软件用于最终组装。
片段通常很短,常在4-10秒左右。每个5秒的片段可能需要多次生成才能获得最终可用版本。
这种工作流程尤其常见于:
- 音乐视频。
- 概念电影。
- 社交媒体实验。
- AI艺术视频。
- 叙事短片。
- 病毒式视觉内容。
关键洞察:逼真AI视频创作正成为一种跨模型工作流程。某个工具可能最适合动作,另一个适合延长,再一个适合音乐,另一个适合脚本编写,还有一个适合最终精修。
案例研究5:受积分限制的Veo 3演示
Veo 3演示案例是AI视频制作中积分问题最清晰的例子之一。
创作者拥有:
| 积分细节 | 数据 |
|---|---|
| 可用积分 | 1,000 |
| 每次生成成本 | 100积分 |
| 理论生成次数 | 大约10次 |
| 实际生成次数 | 两个教育账户共约20次 |
| 最终可用片段 | 5个 |
| 首次成功片段 | 2个 |
| 需要重试的片段 | 3个片段,每个需要3-6次生成 |
这个案例表明,积分可以影响创作过程。如果每次生成都很昂贵,创作者可能会在找到最佳版本之前停止实验。
关键洞察:最佳AI视频模型并非总是最实用的模型。一个工具可能质量极佳,但如果每次尝试的成本很高,它可能难以用于频繁的制作。
案例研究6:1,000个AI视频与1万粉丝
一个以增长为导向的AI视频实验揭示了另一个重要教训。创作者制作了大约1,000个AI视频,并积累了约1万粉丝。
最有用的启示并非视频数量越多就能自动带来增长。更深层次的教训是,视觉逼真度只是整个系统的一部分。
为了观众增长,逼真AI视频仍然需要:
- 强大的创意。
- 清晰的吸引点。
- 可重复的格式。
- 持续发布。
- 良好的节奏。
- 利基定位。
- 可观看的脚本。
- 快速剪辑。
- 可识别的风格。
关键洞察:逼真的视觉效果可能赢得关注,但故事和结构才能留住关注。
制作逼真AI视频的最佳工具是什么?
制作逼真AI视频的最佳工具取决于具体用例。没有普适的最佳选择。正确的选择取决于你是否需要电影感逼真度、角色一致性、产品准确性、唇形同步、片段延长、低成本或高级控制。
电影感逼真度的最佳选择:Kling或Veo
当目标是电影感逼真度时,Kling和Veo是强有力的选择。
Kling适用于短小、连贯、基于参考的逼真片段。当你希望在视觉逼真度和易于制作之间取得良好平衡时,它非常有用。
Veo可以产生高质量的结果,但积分限制可能使实验成本高昂。它可能最适合精选的主镜头、演示片段或高价值场景,而非大规模日常制作。
创意控制的最佳选择:Runway
当目标是创意指导、视觉实验、唇形同步或混合媒体视频时,Runway非常有用。它通常非常适合音乐视频、营销活动概念和实验性AI电影制作。
它可能并非总是适用于所有类型的逼真物理动作的最佳选择,因此通常最好作为更广泛工作流程的一部分来使用。
片段延长的最佳选择:Luma
当你想延长片段、构建转场或连接视觉序列时,Luma非常有用。它通常最适合作为辅助工具,而非工作流程中唯一的工具。
参考图像创建的最佳选择:Midjourney
Midjourney是视频生成开始前最有用的工具之一。它有助于创建强大的视觉参考、角色、情绪板和场景概念。
如果参考图像质量高,视频生成步骤将拥有更好的基础。
最终精修的最佳选择:Topaz
Topaz通常在工作流程的末端使用,用于提升素材分辨率、改善清晰度并提高感知到的制作质量。
Topaz适用于:
- 视频超分辨率。
- 帧增强。
- 谨慎使用时的锐化。
- 提升最终导出质量。
- 使片段更显精美。
但Topaz无法修复糟糕的动作、扭曲的解剖结构或不一致的身份。它是一个后期处理工具,而非逼真度引擎。
最佳用例:在已有干净片段后的最终精修。
高级身份控制的最佳选择:ComfyUI和本地工作流程
高级创作者在需要对身份、参考、成本或自定义进行更多控制时,常使用本地工作流程。
本地工作流程适用于:
- 本地生成。
- 多参考工作流程。
- 角色一致性。
- 更低的边际生成成本。
- 自定义模型工作流程。
- 实验性流程。
- 隐私敏感型制作。
权衡在于复杂性。你可能需要安装ComfyUI、下载模型、配置工作流程、管理GPU资源并学习技术设置。
最佳用例:需要更多控制而非简单操作的高级创作者。
文本转视频 vs 图像转视频:哪个能产生更逼真的结果?
当主体需要保持一致时,图像转视频通常比文本转视频产生更逼真、更可控的结果。文本转视频更适合快速创意生成,而图像转视频更适合逼真的人物、产品、动物、场景和品牌资产。
使用文本转视频进行快速创意
当速度比精确度更重要时,文本转视频非常有用。
将其用于:
- 概念测试。
- 超现实场景。
- 抽象视觉效果。
- 奇幻镜头。
- 背景创意。
- 快速创意探索。
弱点在于控制力。如果你需要同一个人、产品或地点保持稳定,文本转视频可能会变得不可预测。
使用图像转视频制作逼真人物、产品和场景
当逼真度依赖于视觉一致性时,图像转视频表现更佳。
将其用于:
- 逼真的AI人物。
- 产品广告。
- UGC(用户生成内容)风格内容。
- AI虚拟形象片段。
- 动物视频。
- 美食视频。
- 时尚摄影。
- 室内场景。
- 品牌视频。
参考图像为模型提供了一个清晰的锚点。它不能保证完美,但能减少随机性。
使用多参考或本地工作流程确保角色一致性
如果你需要在多个场景中重复使用同一角色,请采用更强大的工作流程。
这可能包括:
- 多个参考图像。
- 角色设定表。
- 一致的种子工作流程。
- ComfyUI流程。
- 本地模型。
- 图像转视频加剪辑。
- 面部或身份控制工具。
这种方法更复杂,但对于AI短片、系列故事、品牌吉祥物和数字人来说通常是必要的。
制作逼真AI视频的成本是多少?
制作逼真AI视频的成本,与其最终视频时长关系不大,而更多取决于你需要多少次生成才能获得可用片段。隐藏成本在于重新生成。
单个AI视频片段可能很便宜,但一个干净、逼真、可发布的片段则未必。
隐藏成本是重新生成
如果一次生成就能创造一个完美的片段,成本就很低。但逼真AI视频很少如此。
你可能需要多次尝试,原因如下:
- 面部扭曲。
- 弱化的动作。
- 糟糕的手部。
- 糟糕的摄像机运动。
- 光照不匹配。
- 产品形状错误。
- 低能量输出。
- 奇怪的背景变化。
例如,在Veo 3演示案例中,5个最终片段需要大约20次生成尝试。这意味着平均每个可用片段需要大约4次尝试。
这就是为什么积分定价很重要。一个输出质量更好的工具,如果失败尝试的成本很高,仍然可能变得昂贵。
免费工具可行,但耗费时间
本地AI短片案例表明,一个逼真的AI视频项目可以直接工具成本为0美元(不含电费和GPU成本)制作。
但时间成本很高:
- 大约1周的工作。
- 有些日子超过12小时。
- 64+张输入图像。
- 36+行对白。
- 3个角色。
- 多个工具和模型。
免费工具可能很强大,但它们并非总是简单易用。
付费工具节省时间,但积分限制创意
付费工具可以减少技术摩擦。它们更容易上手、测试更快,对非技术型创作者更友好。
但它们通常会引入限制:
- 每月积分。
- 生成上限。
- 排队时间。
- 高级模型成本更高。
- 有限的重试次数。
- 分辨率或时长限制。
如果你的工作流程需要大量实验,积分可能会成为瓶颈。
实用预算框架
| 视频类型 | 主要成本驱动因素 | 主要挑战 |
|---|---|---|
| 5-10秒社交片段 | 重新生成 | 干净的动作 |
| 30秒广告 | 积分加剪辑 | 产品和角色一致性 |
| 1-2分钟故事视频 | 多个片段、画外音、剪辑 | 连贯性 |
| 4分钟AI动画 | 数百次实验 | 时间和成本 |
| 本地AI短片 | GPU、设置、时间 | 技术工作流程 |
| AI虚拟形象视频 | 语音、唇形同步、面部稳定性 | 自然呈现 |
最佳预算策略是先测试短片段。在了解你的工具通常需要多少次尝试才能达到你特定风格的效果之前,不要规划长视频。
初学者制作逼真AI视频的常见错误
大多数初学者错误源于期望模型一次性完成过多任务。当你降低复杂性、控制输入并通过剪辑构建最终视频时,逼真AI视频制作效果更佳。
期望一个提示词就能创建成品视频
最大的错误是相信存在一个完美的提示词,能够生成一个逼真的成品视频。
一个提示词无法取代:
- 场景规划。
- 参考图像。
- 多次生成。
- 片段选择。
- 剪辑。
- 声音设计。
- 色彩校正。
- 最终精修。
更好的心态是将提示词视为制作系统的一部分。
使场景过于复杂
复杂的场景更容易失败。
避免在单个片段中包含过多内容:
- 人物过多。
- 动作过多。
- 摄像机运动过多。
- 物体过多。
- 光照变化过多。
- 单个镜头中故事内容过多。
如果一个场景很重要,请将其分解为更小的镜头。
使用冗长但缺乏明确动作方向的提示词
冗长的提示词并非总是好的提示词。有些冗长的提示词描述了风格,但未能清晰描述动作。
对于AI视频,动作是核心。
一个好的提示词应清晰定义:
- 主体。
- 动作。
- 摄像机运动。
- 环境。
- 情绪。
- 什么应该保持一致。
避免使用“使其具有电影感”等模糊短语,而不解释场景中发生了什么。
忽视剪辑和声音
许多AI视频看起来未完成,因为它们止步于生成。但生成并非最终步骤。
没有剪辑和声音,视频往往感觉像一个原始演示。
添加:
- 剪切。
- 节奏。
- 音乐。
- 音效。
- 字幕。
- 画外音。
- 色彩校正。
- 最终导出精修。
追逐工具而非构建可重复的工作流程
AI视频工具变化迅速。新模型不断涌现,旧工具持续改进,定价也在变化。
如果你只追逐最新工具,你的结果可能仍然不稳定。如果你构建一个可重复的工作流程,你可以根据需要更换工具。
最强大的创作者不仅擅长提示词,他们更擅长构建制作系统。
如何为不同用例制作逼真AI视频
不同的用例需要不同的逼真AI视频工作流程。TikTok视频、产品广告、短片、AI虚拟形象和教育视频不应以相同的方式制作。
适用于TikTok和Instagram的AI视频
对于短视频社交平台,逼真度固然重要,但吸引点更重要。
最佳实践:
- 在第一秒就以强烈的视觉效果开场。
- 保持片段简短。
- 使用字幕。
- 添加音乐或音效。
- 快速剪辑。
- 避免长时间停留在面部或手部。
- 构建可重复的格式。
- 每个视频只专注于一个创意。
社交AI视频无需完美。它们需要具有可看性、清晰度和趣味性。
适用于AI广告和产品视频
对于产品视频,一致性比视觉奇观更重要。
产品不应变形。标志不应扭曲。使用场景应清晰。观众应理解产品是什么以及它为何重要。
最佳实践:
- 使用干净的产品参考图像。
- 避免过于复杂的产品动作。
- 使用特写镜头。
- 在情境中展示产品。
- 保持光照一致。
- 使用文本叠加解释优势。
- 不要只依赖电影感视觉效果。
如果产品在不同镜头中看起来不同,那么逼真的产品视频就会失败。
适用于AI短片
AI短片需要的不仅仅是良好的视觉效果。它们需要故事结构。
最佳实践:
- 首先编写脚本。
- 将故事分解为场景。
- 为每个场景创建参考图像。
- 保持镜头简短。
- 使用重复的视觉规则。
- 谨慎添加对白。
- 使用音乐和声音设计。
- 为情感而非仅仅美学进行剪辑。
本地AI短片案例就是一个很好的例子。它需要64+张独特的输入图像、36+行对白、3个角色和大约1周的工作。这比随意编写提示词更接近实际制作。
适用于AI虚拟形象和“讲话头”视频
AI虚拟形象视频依赖于面部稳定性、语音质量、唇形同步和自然呈现。
最佳实践:
- 使用干净的面部参考。
- 保持光照柔和稳定。
- 避免极端的头部转动。
- 使用自然的语音节奏。
- 添加字幕。
- 保持背景简单。
- 仔细测试唇形同步。
- 避免没有剪切的过长独白。
对于“讲话头”视频,观众的注意力集中在面部。微小的错误也会变得显而易见。
适用于培训和教育视频
教育AI视频并非总是需要电影感逼真度。它们需要清晰度、一致性和易于更新。
最佳实践:
- 使用清晰的旁白。
- 使用幻灯片、图表或屏幕视觉效果。
- 保持虚拟形象稳定。
- 避免不必要的电影感效果。
- 将课程分解为短模块。
- 添加字幕。
- 使视频易于后期修改。
对于培训内容,目标不是用AI给观众留下深刻印象。目标是帮助他们理解和记住材料。
发布前逼真AI视频检查清单
在发布逼真AI视频之前,请像制作人一样审阅,而不仅仅是提示词编写者。一个片段初看可能令人印象深刻,但仔细检查时可能会暴露出问题。
视觉质量检查清单
请问:
- 面部是否稳定?
- 手部看起来是否可接受?
- 身体动作是否自然?
- 主体是否保持同一身份?
- 产品是否保持相同形状?
- 光照是否一致?
- 背景是否稳定?
- 是否有可见的故障?
- 摄像机运动是否感觉有目的性?
- 首帧和尾帧是否干净?
如果一个片段未能通过其中几项检查,请重新生成或剪掉它。
故事和剪辑检查清单
请问:
- 前2秒是否能引起兴趣?
- 每个片段都有其目的吗?
- 节奏是否过慢?
- 有缺陷的帧是否被移除?
- 转场是否自然?
- 序列是否易于理解?
- 视频是否有清晰的开头、中间和结尾?
- 创意是否比视觉效果更强大?
一个没有结构的逼真视频仍然感觉像一个演示。
音频和最终精修检查清单
请问:
- 语音是否清晰?
- 音乐是否与场景匹配?
- 音效是否可信?
- 字幕是否可读?
- 色彩校正是否一致?
- 导出质量是否足够高?
- 视频是否感觉像一个完整的作品?
- 有人会观看它,而不介意它是用AI制作的吗?
最后一个问题才是真正的考验。最好的逼真AI视频不会让观众思考工具,而是让他们专注于场景、故事、产品或信息。
常见问题:关于制作逼真AI视频的真实疑问
人们如何制作逼真的AI视频?
人们通过结合参考图像、图像转视频工具、短片段生成、反复重新生成、剪辑、声音设计、超分辨率和色彩校正来制作逼真AI视频。大多数逼真AI视频并非通过一个提示词制作,而是由多个干净的片段组装而成。
人们正在使用哪些工具制作逼真的AI视频?
常用工具包括Kling、Runway、Luma、Veo、Midjourney、Topaz、ComfyUI、Wan相关工作流程、本地视频模型、语音工具、音乐工具和剪辑软件。最佳工具取决于具体用例。
逼真AI视频是用Sora、Kling、Runway还是完整工作流程制作的?
大多数逼真AI视频都是通过完整的工作流程制作的。Kling、Runway、Veo或Sora等工具可能生成片段,但最终结果通常还取决于参考图像、重新生成、剪辑、音频、超分辨率和色彩校正。
文本转视频还是图像转视频更适合逼真AI视频?
当你需要一致的人物、产品、动物或场景时,图像转视频通常能产生更逼真的结果。文本转视频更适合快速创意和探索。
创作者如何在AI视频中保持同一角色?
他们通常使用参考图像、短片段、一致的提示词、多参考工作流程、角色设定表、图像转视频工具和仔细的剪辑。对于高级控制,一些创作者会使用ComfyUI或本地工作流程。
为什么我的AI视频即使提示词很详细,仍会出现随机故障?
详细的提示词并不能保证物理一致性。故障通常发生是因为场景过于复杂、动作不清晰、片段过长、参考图像质量差,或者模型无法在帧之间保持身份和动作。
制作逼真视频的最佳AI视频生成器是什么?
对于每个项目,没有单一的最佳AI视频生成器。Kling擅长连贯的逼真短片段。Veo可以产生高质量输出,但可能受积分限制。Runway适用于创意控制和唇形同步。Luma适用于延长片段。本地工作流程提供高级控制。
如何防止AI视频中的面部扭曲?
使用干净的参考图像、保持片段简短、避免极端的头部运动、生成多个版本、使用图像转视频而非纯文本转视频,并在剪辑时移除有缺陷的帧。
如何减少手部扭曲和身体变形?
使用更简单的动作、避免复杂的全身场景、让手部远离注意力中心、将复杂动作分解为多个镜头,并选择最干净的生成片段。
免费或低成本工具能否制作逼真AI视频?
是的,但它们通常需要更多时间和技术技能。我研究中的一个本地AI短片案例,直接工具成本为0美元(不含电费和GPU成本),但需要大约1周的工作、64+张输入图像、36+行对白和长时间的制作。
为什么AI视频常常看起来像慢动作?
AI模型有时会选择缓慢或最小的动作,因为它比复杂的物理动作更安全。要改善这一点,请使用清晰的动作动词、简单的动作、更好的参考,以及擅长处理动作的工具。
如果模型只能生成短片段,人们如何制作长AI视频?
他们通过生成许多短片段、选择最佳输出、将它们拼接起来、添加转场、统一色彩、添加音频,并将序列剪辑成一个完整的故事来制作长AI视频。
制作逼真AI视频的成本是多少?
成本取决于你需要多少次生成。一个短片段可能很便宜,但一个干净逼真的片段可能需要多次尝试。我研究中的一个4分钟AI动画故事需要500多次生成视频实验,成本超过1,000美元。
如何让AI视频看起来不那么虚假?
使用参考图像、保持片段简短、生成多个版本、选择干净的输出、剪掉有缺陷的帧、添加逼真的声音、使用字幕、对最终视频进行色彩校正,并在需要时应用微妙的胶片颗粒或超分辨率。
AI视频可以用于产品广告吗?
是的,但产品一致性至关重要。使用清晰的产品参考图像、避免复杂的变形、保持产品形状稳定,并利用剪辑结合特写镜头、生活方式镜头和以优势为导向的文本叠加。
最终总结:逼真AI视频源于工作流程,而非神奇提示词
逼真AI视频并非通过在一个完美工具中输入一个完美提示词就能制作出来。它们是通过结合规划、参考图像、短片段生成、反复筛选、剪辑、音频、超分辨率和最终精修的工作流程制作的。
取得最佳效果的创作者不仅擅长提示词,他们更擅长构建制作系统。
随着AI视频工具的改进,优势将从“谁拥有最好的模型”转向“谁拥有最好的工作流程、故事和剪辑过程”。逼真AI视频不仅仅是一个生成的片段,它是一个完整的媒体作品。







